 向东进版-多元统计分析课后习题答案Word文档格式.doc
向东进版-多元统计分析课后习题答案Word文档格式.doc
- 文档编号:339068
- 上传时间:2023-04-28
- 格式:DOC
- 页数:17
- 大小:1.50MB
向东进版-多元统计分析课后习题答案Word文档格式.doc
《向东进版-多元统计分析课后习题答案Word文档格式.doc》由会员分享,可在线阅读,更多相关《向东进版-多元统计分析课后习题答案Word文档格式.doc(17页珍藏版)》请在冰点文库上搜索。
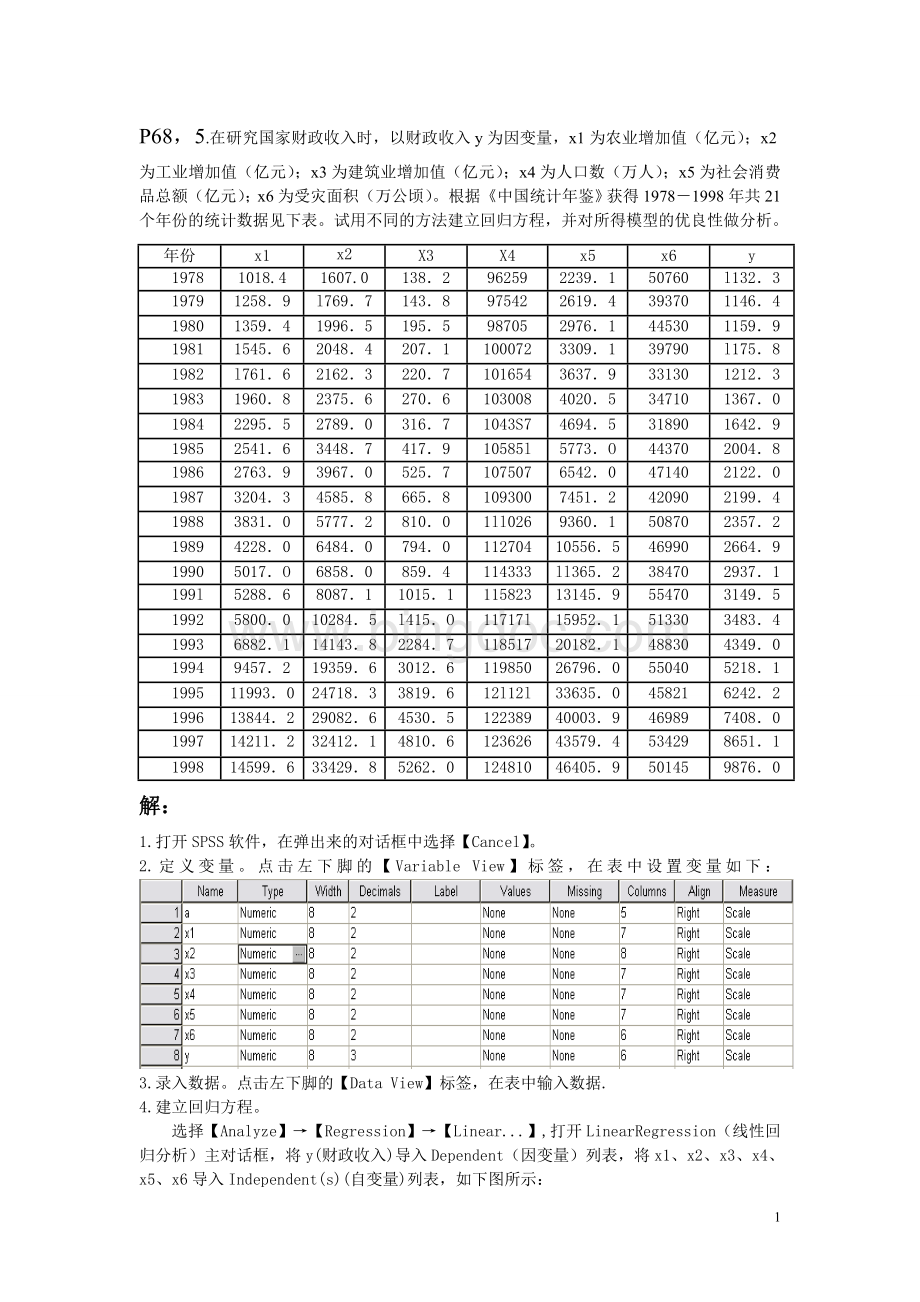
4020.5
34710
1367.0
1984
2295.5
2789.0
316.7
1043S7
4694.5
31890
1642.9
1985
2541.6
3448.7
417.9
10585l
5773.O
44370
2004.8
1986
2763.9
3967.0
525.7
107507
6542.0
47140
2122.0
1987
3204.3
4585.8
665.8
109300
7451.2
42090
2199.4
1988
3831.0
5777.2
810.0
1ll026
9360.1
50870
2357.2
1989
4228.0
6484.0
794.0
112704
10556.5
46990
2664.9
1990
5017.O
6858.0
859.4
114333
ll365.2
38470
2937.1
199l
5288.6
8087.1
1015.1
115823
13145.9
55470
3149.5
1992
5800.0
10284.5
l415.O
11717l
15952.1
51330
3483.4
1993
6882.1
14143.8
2284.7
118517
20182.1
48830
4349.0
1994
9457.2
19359.6
3012.6
119850
26796.0
55040
5218.1
1995
11993.0
24718.3
3819.6
12l12l
33635.0
45821
6242.2
1996
13844.2
29082.6
4530.5
122389
40003.9
46989
7408.0
1997
14211.2
32412.1
4810.6
123626
43579.4
53429
8651.1
1998
14599.6
33429.8
5262.0
124810
46405.9
50145
9876.0
解:
1.打开SPSS软件,在弹出来的对话框中选择【Cancel】。
2.定义变量。
点击左下脚的【VariableView】标签,在表中设置变量如下:
3.录入数据。
点击左下脚的【DataView】标签,在表中输入数据.
4.建立回归方程。
选择【Analyze】→【Regression】→【Linear...】,打开LinearRegression(线性回归分析)主对话框,将y(财政收入)导入Dependent(因变量)列表,将x1、x2、x3、x4、x5、x6导入Independent(s)(自变量)列表,如下图所示:
如图所示,Method(方法)下拉菜单,可以指定自变量进入分析的方法。
通过选择不同的方法,可对相同的变量建立不同的回归模型,建立多重回归的方法有5种:
Enter(强迫引入法),Stepwise(逐步回归法),Remove(强迫剔除法),Backward(后向消去法),Forward(前向逐步法)。
5单击【Statistics...】按钮,打开LinearRegression:
Statistics(统计量)对话框,如下图所示:
如图所示,在RegressionCoefficients(回归系数)选项中,选择了Estimates(估计值)——显示回归系数B、SEB、标准化回归系数(Bate)、B的t值及双侧显著性水平(sig.);
Confidenceintervals(致信区间)——显示每个回归系数的95%置信区间或协方差矩阵;
Covariancematrix(协方差矩阵)——显示B的方差-协方差矩阵,相关系数矩阵;
Modelfit(模型拟合)——显示被引入模型或剔除的变量及拟合优度统计量,复相关系数R、R2调整R2,估计值的标准误差及方差分析表。
colinearitydiagnostics显示共线性问题.
在Residuals(残差统计量)选项中,选择Durbin-Watson选项,同时显示标准化与非标准化残差与预测值的汇总统计量。
6单击【Continue】→【Plots...】按钮,打开LinearRegression:
Plots(图形)
对话框,如下图所示:
此处选择了一个Scatter(散点图),它是以DEPENDNT(因变量)作为Y轴,以*ZRESID(标准化残差)为X轴;
同时还选择了Normalprobabilityplot(正态概率图,即P-P图),和Histogram标准化残差的直方图并给出正态曲线。
7单击【Continue】→【Save...】按钮,打开LinearRegression:
Save(保存)对话框,如下图所示:
此处在PredictedValues(预测值)中选择了Unstandardized(非标准化预测值),和Standardized(标准化预测值);
在PredictionIntervals(预测区间)选择Individual(个体预测区间)和mean,根据题目要求,设置ConfidenceInterval(置信区间)为95%。
8单击【Continue】→【OK】按钮,得到主要结果。
逐步回归法:
1.此表显示的是变量的引入与剔除,以及选用的方法。
VariablesEntered/Removed(a)
Model
VariablesEntered
VariablesRemoved
Method
1
.
Stepwise(Criteria:
Probability-of-F-to-enter<
=.050,Probability-of-F-to-remove>
=.100).
aDependentVariable:
y
2.下表显示的是模型摘要。
从表中可以得出:
复相关系数R2=0.989和修正的复相关系数R2a=0.988接近于1,这说明模型的拟合优度比较高;
DW统计量为0.822,用于判别该模型是否存在一阶自相关。
ModelSummary(b)
R
RSquare
AdjustedRSquare
Std.ErroroftheEstimate
Durbin-Watson
.994(a)
.989
.988
285.479745
.822
aPredictors:
(Constant),x5
bDependentVariable:
3.下表是方差分析表。
从表中可以得到有关SSR,SSE,SST的平方和、自由度和均方差等信息,以及MSR,MSE的值,如表中所示,F值为1669.841,Sig.值小于给定α,表示此回归方程通过显著性检验。
ANOVA(b)
SumofSquares
df
MeanSquare
F
Sig.
Regression
136089861.032
1669.841
.000(a)
Residual
1548475.008
19
81498.685
Total
137638336.040
20
4.下表表示的是有关回归系数的信息。
从表中可以看出,β0=695.441,β1=0.180,经过标准化处理后,β1×
=0.994,且x5的回归系数的Sig.值均小于给定的α=0.05,即通过了显著性检验。
y关于x5的非标准化的二元线性回归方程为:
y=695.441+0.180x5y关于x5标准化的二元线性回归方程为:
y=659.441+0.994x5
Coefficients(a)
UnstandardizedCoefficients
StandardizedCoefficients
t
95%ConfidenceIntervalforB
CollinearityStatistics
B
Std.Error
Beta
LowerBound
UpperBound
Tolerance
VIF
1(Constant)
x5
695.441
90.826
7.657
.000
505.340
885.542
.180
.004
.994
40.864
.171
.190
1.000
5.由直方图中显示,总体分布接近正态分布。
6.上图右为残差的正态概率图,即P-P图。
从图中可以看到,点(q(i),e(i))近似在一条直线上,且e(i)与q(i)之间的相关系数非常接近于1,从而可以认为本题中误差正态性的假设是合理的。
差分法:
VariablesEntered/Removed(a)
ModelSummary(b)
.895(a)
.802
.790
192.69509
1.255
(Constant),x2
x2
63.704
59.666
1.068
.301
.205
.025
.895
8.286
后退法结果:
ModelSummary(e)
.996(a)
.993
.990
265.126904
2
.996(b)
256.871503
3
.996(c)
.991
250.624597
4
.996(d)
.992
249.693601
1.476
(Constant),x6,x3,x1,x4,x5,x2
bPredictors:
(Constant),x6,x1,x4,x5,x2
cPredictors:
(Constant),x1,x4,x5,x2
dPredictors:
(Constant),x4,x5,x2
eDependentVariable:
ANOVA(e)
前进法结果:
(Constant)
结果分析:
该题我共用了四种方法.从上述结果中可以发现逐步回归法的计算结果与前进法的结果完全相同。
比较上述三种不同计算结果,可以发现无论哪一个模型,都大致满足回归分析的基本假定,通过了显著性检验。
前进法(逐步回归法)只选入了一个自变量x5,VIF值为1,说明不存在多重共线性得问题,但是DW值为0.822,不在2左右,说明模型存在一阶自相关.可能是回归模型选用不当,也可能是缺少重要的自变量,应加入相应的自变量.
enter法全模型虽通过显著性检验,DW值也趋于2,但是只有变量x5通过了显著性检验,x2、x3、x4、x5的方差扩大因子(VIF)分别为2518.961、447.819、19.028和2220.810,说明这四个变量之间存在严重的多重共线性,需要剔除一些不重要的自变量.
而后退法选了3个自变量(x4,x5,x2),利用书中介绍的选择最优准则来判断,逐步回归法是最优的。
它们与后退法之间的主要差异是所选择的变量不同。
P98,2.某商学院在招收研究生时,以学生在大学期间的平均学分x1与管理能力考试成绩x2帮助录取研究生。
对申请者划归为3类。
G1:
录取;
G2:
未录取;
G3:
待定。
下表记录了近期报考者的值和录取情况。
序号
分组
2.96
596
30
3.76
546
59
2.90
384
3.14
473
31
3.24
467
60
2.86
494
3.22
482
32
2.54
446
61
2.85
498
3.29
527
33
2.43
425
62
419
5
3.69
505
34
2.20
474
63
3.28
371
6
3.46
693
35
2.41
531
64
2.89
447
7
3.03
626
36
2.19
542
65
3.15
313
8
3.19
663
37
3.35
406
66
3.50
402
9
3.63
38
2.51
412
67
485
10
3.59
588
39
458
68
2.80
444
11
3.30
563
40
2.36
399
69
3.13
416
12
3.40
553
41
70
3.01
471
13
572
42
2.66
420
71
2.79
490
14
3.78
591
43
2.68
414
72
431
15
3.44
692
44
2.48
533
73
2.91
466
16
3.48
528
45
2.46
509
74
2.75
17
3.47
552
46
2.63
504
75
2.73
18
520
47
2.44
366
76
3.12
463
3.39
543
48
2.13
408
77
3.08
440
523
49
469
78
21
3.21
530
50
2.55
538
79
3.00
22
3.58
564
51
2.31
80
438
23
3.33
565
52
81
3.05
24
53
411
82
483
25
3.38
605
54
2.35
321
83
453
26
3.26
664
55
2.60
394
84
27
3.60
609
56
85
3.04
28
3.37
559
57
2.72
3.61
513
29
3.80
521
58
381
497
(1)先验概率相等的假定下,进行Bayes判别,并确定回代和交叉确认误判率;
(2)在先验概率相由样本比例计算得假定下:
进行Bayes判别,并确定回代和交叉确认误判率;
(3)设有两名新申请者的(X1,X2)分别为(3.61,513)和(2.91,497),利用所建立判别准则判别他们应该归为哪一类?
进行判别分析:
①选择【Analyze】→【Classify】→【Discriminant...】,打开DiscriminantAnalysis(判别分析)主对话框,如下图所示:
把group导入GroupingVariable(分组变量),并单击【DefineRange…】,在弹出来的对话框中,定义判别数据的类别区间,设定Minimun为1,Maximum为3,单击【Continue】,返回上图所示的对话框;
将平均学分x1与管理能力考试成绩x2导入Independent(s)(自变量)列表;
本题我选用逐步的方法选择变量进入方程,因此选择Usestepwisemethod。
②单击【Statistics...】按钮,打开DiscriminantAnalysis:
Statistics(统计量)对话框。
如下图所示,在Descriptives(描述性统计量)中选择Means(平均数)要求对各组的个变量做均数与标准差的描述。
在FunctionCoefficients(判别函数系数)一栏中选择了unstandarddized,要求显示判别方程的非标准化系数。
③点击“Classify...”,打开DiscriminantAnalysis:
Classify(分类)对话框,如下图所示:
根据题目第一问要求,在PriorProbabilities(先验概率)一栏中,选择Allgroupsequal,即假设各类先验概率均相等。
在Display一栏中选择了Casewiseresults——显示每个个案的实际分组、预测分组后验概率及判别分数。
显示摘要和Leave-one-out分类表;
在另外两栏中分别选择了组内协方差矩阵和区域图。
⑤单击【Continue】→【OK】按钮,得到主要结果。
5.结果及分析
①此图显示的是分组统计量。
它显示了各组变量的统计量、总变量的均数以及标准差。
②此图显示的是分组均数齐性检验,从图中可以看出Wilksλ检验:
x1(P<
0.01),


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 东进 多元 统计分析 课后 习题 答案
 冰点文库所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰点文库所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 甲醇合成的仿真实验报告.docx
甲醇合成的仿真实验报告.docx
-
动态分区分配方式的模拟C语言代码和C++代码.doc
-
复合肥成品检验报告单.docx
-
优秀团员个人事迹材料.docx
-
PDCA项目-降低非计划性拔管发生率持续改进.doc
-
丙型肝炎病毒实验活动风险评估报告.docx
-
开展大兴调查研究工作方案三篇.docx
-
受限空间作业施工方案.doc
-
车辆安全管理制度..docx
-
丙型肝炎病毒实验活动风险评估报告(精品二篇).docx
-
创客中心建设方案设计.doc
-
CAN总线与RS-232转换接口电路设计.doc
 建筑LEC危险源辨识清单.xls
建筑LEC危险源辨识清单.xls
-
【公开课教案】《印度》第一课时教学设计.docx
-
风力发电工程质量监督检查大纲.doc
-
部编版语文四年级下册《宝葫芦的秘密》节选 公开课省级一等奖教学设计.docx
-
车辆安全管理制度.docx
-
代职总结.docx
-
小王子最经典的语录.docx
-
数据共享交换平台实施方案.docx
-
管理制度咨询公司管理制度制度(制度范本).docx
-
高层图书馆给排水毕业设计.docx
-
(完整版)常用词根词缀表(综合整理).docx
-
健康宣教|为爱急救:学会心肺复苏.docx
-
小学2022年度学校工作计划——以和美教育理念为引领 创造和美教育新生活..docx
-
Seminar教学模式研究综述-精选教育文档.docx
-
幼儿教育课题申报书:基于农村田园资源的幼儿园劳动教育的实践研究.docx
-
国家机关政府部门公文标准格式(2021最新版).docx
-
云教版五年级劳动技术教案下册(改).doc
-
学校反恐防暴自查报告 (5).docx
-
社区网格化管理精细化服务工作汇报.docx
-
公路施工现场安全标志和安全防护设施设置.doc
-
精品职业安全卫生测试题答案.docx
-
配套K12七年级生物下册第四单元第四章第四节输血与血型同步测试新版.docx
-
精选《非暴力沟通》读后感15篇.docx
-
曝光的基本理论分析.docx
-
精选护士个人述职报告总结范文.docx
-
企业经营战略.docx
-
企业培训市场现状分析.docx
-
精选学年八年级英语上册Unit8Howdoyoumakeabananamilkshake单元综合测试题2新版人教新目标版.docx
-
企业信息构架服务.docx
-
精遗传学有关简答题型归类及复习策略.docx
-
气动型吸取机械臂设计说明书.docx
-
竞选家长委员会发言稿精选多篇.docx
-
汽车空调练习题库.docx
-
九江市重点实验室认定申请书.docx
-
九年级下期工作计划.docx
-
汽车维修中级工理论试题.docx
-
九年级语文上册第五单元复习知识梳理.docx
-
汽机本体安装作业指导书.docx
-
酒店前台培训计划7篇.docx
