 12132《数据分析》实验指导书Word文档格式.docx
12132《数据分析》实验指导书Word文档格式.docx
- 文档编号:6902195
- 上传时间:2023-05-07
- 格式:DOCX
- 页数:28
- 大小:62.43KB
12132《数据分析》实验指导书Word文档格式.docx
《12132《数据分析》实验指导书Word文档格式.docx》由会员分享,可在线阅读,更多相关《12132《数据分析》实验指导书Word文档格式.docx(28页珍藏版)》请在冰点文库上搜索。
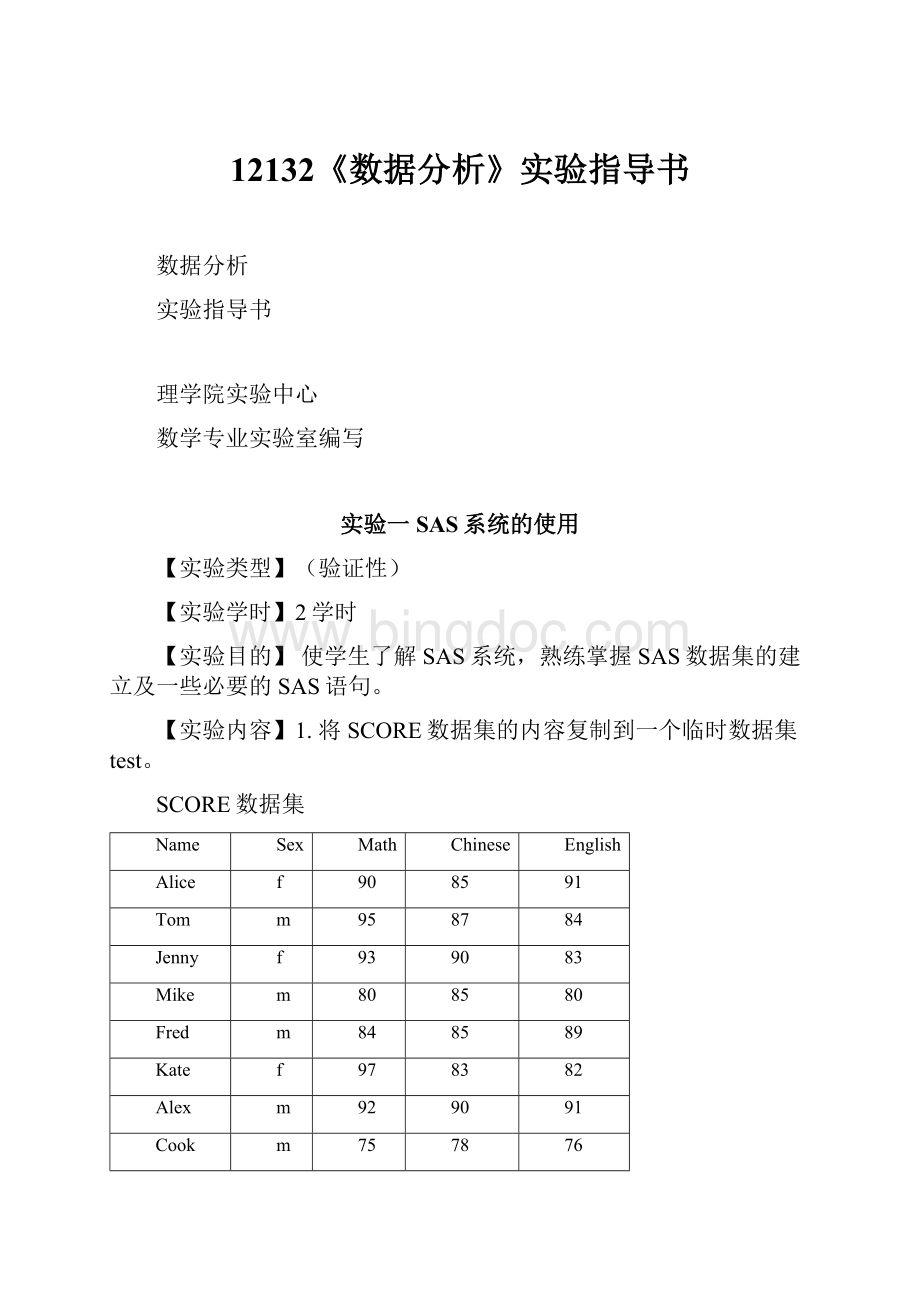
两数据集的并接:
若两个数据集的数据行数(即观测向量个数)相同且按相同顺序排列,可将两数据集并接以形成新的SAS数据集,其中数据集中变量的个数为原两数据集中的变量个数之和.
MERGEAB;
2)两个数据集的复制
DATAA;
/A为新的数据集/
SETB;
/B为要复制的数据集名/
KEEPvariables;
/希望保留的变量名/
DROPvariables;
/希望去掉的变量名/
3)两个数据集的拆分
示例:
将记录学生成绩的//数据集按性别分成两个数据集,即一个记录男生的成绩,一个记录女生的成绩。
程序如下:
Datascoremscoref;
Setsasuser.score;
Select(sex);
When(‘m’)outputscorem;
When(‘f’)outputscoref;
End;
Run;
dataa1a2;
seta;
select;
when(x1>
90)outputa1;
when(x1=<
90)outputa2;
end;
run;
【实验报告要求】1.写出程序设计;
2.附上程序运行的结果。
实验二 上市公司的数据分析
(综合性)
【实验目的】通过使用SAS软件对实验数据进行描述性分析和回归分析,熟悉数据分析方法,培养学生分析处理实际数据的综合能力。
【实验内容】表2是一组上市公司在2001年的每股收益(eps)、流通盘(scale)的规模以及2001年最后一个交易日的收盘价(price).
表2某上市公司的数据表
代码
流通盘
每股收益
股票价格
000096
8500
0.059
13.27
000099
6000
0.028
14.2
000150
12600
-0.003
7.12
000151
10500
0.026
10.08
000153
2500
0.056
22.75
000155
13000
-0.009
6.85
000156
3600
0.033
14.95
000157
10000
0.06
12.65
000158
0.018
8.38
000159
7000
0.008
12.15
000301
15365
0.04
7.31
000488
7700
0.101
13.26
000725
0.044
12.33
000835
1338
0.07
22.58
000869
3200
0.194
18.29
000877
7800
-0.084
12.55
000885
-0.073
12.48
000890
16934
0.031
9.12
000892
12000
7.88
000897
14166
0.002
6.91
000900
21423
0.058
8.59
000901
4800
0.005
27.95
000902
6500
-0.031
10.92
000903
0.109
11.79
000905
9500
0.046
9.29
000906
6650
0.007
14.47
000908
8988
0.006
8.28
000909
9.99
000910
8000
0.036
8.9
000911
7280
0.067
9.01
000912
15000
0.112
8.06
000913
8450
0.062
11.86
000915
4599
0.001
14.4
000916
34000
0.038
5.15
000917
11800
0.086
16.23
000918
-0.045
10.12
1、对股票价格
1)计算均值、方差、标准差、变异系数、偏度、峰度;
2)计算中位数,上、下四分位数,四分位极差,三均值;
3)作出直方图;
4)作出茎叶图;
5)进行正态性检验(正态W检验);
6)计算协方差矩阵,Pearson相关矩阵;
7)计算Spearman相关矩阵;
8)分析各指标间的相关性。
2、1)对股票价格,拟合流通盘和每股收益的线性回归模型,求出回归参数估计值及残差;
2)给定显著性水平α=0.05,检验回归关系的显著性,检验各自变量对因变量的影响的显著性;
3)拟合残差关于拟合值
的残差图及残差的正态QQ图。
分析这些残差,并予以评述。
【实验前的预备知识】
1、1)数据的数字特征:
均值、方差、中位数、三均值与极差等;
2)数据的分布:
直方图、茎叶图、箱线图、正态性检验等;
3)多元数据的数字特征与相关性分析:
均值向量与协方差矩阵等。
2、1)线性回归模型的参数估计及有关的统计推断;
2)残差分析。
1、数据描述性分析SAS程序的主要语句形式
1)PROCMEANS过程
PROCMEANSoptions;
VARvariables;
/指出数据集中要计算的变量名称(应是数值变量)/
OUTPUTOUT=SASdatasetkeyword=name…;
/建立一个由PROCMEANS过程的分析结果构成的SAS数据集/
其中“options”包含下列内容的部分或全部:
a.DATA=SASdataset:
指明所要分析的SAS数据集名称.若省略此选项,则对最新建立的数据集作分析.
b.MAXDEC=
:
其中
为介于0与8之间的一个正整数,该选项指明在输出数据时小数点后保留
位.
c.关键词:
逐个列出要计算其值的统计量名称的关键词,最常用的有N(变量的观测值个数)、MEAN(均值)、STD(标准差)、VAR(方差)、MIN(各变量观测值的最小值)、MAX(各变量观测值的最大值)、RANGE(极差)、SUM(总和)、USS(平方和)、CSS(中心化平方和)、SKEWNESS(偏度)、KURTOSIS(峰度)、T(对每个变量的均值是否为零进行双边
检验)、PRT(双边的
值).
2)PROCUNIVARIATE过程
PROCUNIVARIATEoptions;
PLOTvariable1;
OUTPUTOUT=SASdatasetkeyword=name
;
指明所要分析的SAS数据集名称.
b.PLOT:
要求对所分析的各变量的观测值产生一个茎叶图(或水平直方图)、一个箱线图和一个正态QQ图.若某区间的观测值超过48,则不绘制茎叶图,而改绘水平直方图,在正态QQ图中,以“*”号标示正态QQ图上的点,以“+”标示相应的参考直线.
c.FREQ:
要求生成包括变量值、频数、百分数和累计百分数的表.
d.NORMAL:
要求对分析的各变量的观测值是否来自正态分布总体做检验,并输出检验的
值.
3)PROCCORR过程
PROCCORRoptions;
WITHvariables;
b.PEARSON:
要求输出Pearson相关系数矩阵(为默认输出结果).
c.SPEARMAN:
要求输出Spearman秩相关系数矩阵.
d.COV:
要求计算协方差矩阵.
e.NOSIMPLE:
指明不输出每个变量的简单描述性统计量的值.
VARvariables:
该语句指出要计算相关系数矩阵或协方差阵的变量名称,可以是数据集中数值变量的一部分.
WITHvariables:
此语句和“VARvariables”语句合用,可以得到变量间特殊组合的相关系数矩阵,即“VAR”后的各变量与“WITH”后的各变量间的相关系数矩阵。
2、回归分析过程的主要语句形式
PROCREGoptions;
MODELdependent=regressors/options;
OUTPUTOUT=SASdatasetkeyword=names…;
1)PROCREGoptions;
“options”部分应指出要分析的SAS数据集;
2)关键词“MODEL”之后,应指明因变量,等号之后依次列出回归变量,options包括
a.SELECTION=name,其中“name”可以是FORWARD(向前选择最优模型方法),BACKWORD(向后删除法),STEPWISE(逐步回归法),RSQUARE(利用
准则选取最优模型的方法),ADJRSQ(即利用修正的
准则选择最优模型法),CP(利用
准则选择最优模型法);
b.对模型选取细节的选项:
DETAILS:
此选项仅对最优模型选取方法中的FORWARD、BACKWORD、STEPWISE有效,它要求打印出每一步引入和删除的自变量及相关信息;
NOINT取消回归模型的常数项,拟合过原点的回归方程;
c.对估计细节内容的选择:
CORRB:
打印出估计的参数的相关系数矩阵;
COVB:
打印出估计的参数的协方差矩阵;
P:
打印出因变量的拟合值;
R:
打印出有关残差及用于影响性分析的各量,包括拟合值的标准差、残差、学生化残差及Cook距离。
3)OUTPUTOUT=SASdatasetkeyword=names…;
此语句除包含所分析的原SAS数据集的全部内容外,keyword后可以指定下列的一些或全部内容:
P=name:
因变量的拟合值
R=name:
残差
STUDENT=name:
标准化残差
L95M=name:
因变量的期望值的95%置信区间的置信下限
U95M=name:
因变量的期望值的95%置信区间的置信上限
L95=name:
因变量真值的95%置信区间的置信下限
U95=name:
因变量真值的95%置信区间的置信上限
COOK=name:
Cook距离,用以影响性分析的统计量
H=name:
杠杆量,即
,
是设计矩阵
的第i行
PRESS=name:
用以估计第i组观测值对拟合值的影响
DFFITS=name:
用以估计第i组观测值对参数估计的影响
【实验报告要求】
1.简述实验原理;
2.写出程序设计;
3.按程序附上分析的结果,结合数据背景对结果给出合理的解释。
实验三 美国50个州七种犯罪比率的数据分析
【实验目的】通过使用SAS软件对实验数据进行主成分分析和因子分析,熟悉数据分析方法,培养学生分析处理实际数据的综合能力。
【实验内容】表3给出的是美国50个州每100000个人中七种犯罪的比率数据。
这七种犯罪是:
Murder(杀人罪),Rape(强奸罪),Robbery(抢劫罪),Assault(斗殴罪),Burglary(夜盗罪),Larceny(偷盗罪),Auto(汽车犯罪)。
表3美国50个州七种犯罪的比率数据
State
Murder
Rape
Robbery
Assault
Burglary
Larceny
Auto
Alabama
25.2
96.8
278.3
1135.5
1881.9
280.7
Alaska
10.8
51.6
284.0
1331.7
3369.8
753.3
Arizona
9.5
34.2
138.2
312.3
2346.1
4467.4
439.5
Arkansas
8.8
27.6
83.2
203.4
972.6
1862.1
183.4
California
11.5
49.4
287.0
358.0
2139.4
3499.8
663.5
Colorado
6.3
42.0
170.7
292.9
1935.2
3903.2
477.1
Connecticut
4.2
16.8
129.5
131.8
1346.0
2620.7
593.2
Delaware
6.0
24.9
157.0
194.2
1682.6
3678.4
467.0
Florida
10.2
39.6
187.9
449.1
1859.9
3840.5
351.4
Georgia
11.7
31.1
140.5
256.5
1351.1
2170.2
297.9
Hawaii
7.2
25.5
128.0
64.1
1911.5
3920.4
489.4
Idaho
5.5
19.4
172.5
1050.8
2599.6
237.6
Illinois
9.9
21.8
211.3
209.0
1085.0
2828.5
528.6
Indiana
7.4
26.5
123.2
153.5
1086.2
2498.7
377.4
Iowa
2.3
10.6
41.2
89.8
812.5
2685.1
219.9
Kansas
6.6
22.0
100.7
180.5
1270.4
2739.3
244.3
Kentucky
10.1
19.1
81.1
123.3
872.2
1662.1
245.4
Louisiana
15.5
30.9
142.9
335.5
1165.5
2469.9
337.7
Maine
2.4
13.5
38.7
170.0
1253.1
2350.7
246.9
Maryland
8.0
34.8
292.1
358.9
1400.0
3177.7
428.5
Massachusetts
3.1
20.8
169.1
231.6
1532.2
2311.3
1140.1
Michigan
9.3
38.9
261.9
274.6
1522.7
3159.0
545.5
Minnesota
2.7
19.5
85.9
85.8
1134.7
2559.3
343.1
Mississippi
14.3
19.6
65.7
189.1
915.6
1239.9
144.4
Missouri
9.6
28.3
189.0
233.5
1318.3
2424.2
378.4
Montana
5.4
16.7
39.2
156.8
804.9
2773.2
309.2
Nebraska
3.9
18.1
64.7
112.7
760.0
2316.1
249.1
Nevada
15.8
49.1
323.1
355.0
2453.1
4212.6
559.2
NewHampshire
3.2
10.7
23.2
76.0
1041.7
2343.9
293.4
NewJersey
5.6
21.0
180.4
185.1
1435.8
2774.5
511.5
NewMexico
39.1
109.6
343.4
1418.7
3008.6
259.5
NewYork
29.4
472.6
319.1
1728.0
2782.0
745.8
NorthCarolina
17.0
61.3
318.3
1154.1
2037.8
192.1
Ohio
7.8
27.3
190.5
181.1
1216.0
2696.8
400.4
NorthDakota
0.9
9.0
13.3
43.8
446.1
1843.0
144.7
Oklahoma
8.6
29.2
73.8
205.0
1288.2
2228.1
326.8
Oregon
4.9
39.9
124.1
286.9
1636.4
35061
388.9
Pennsylvania
19.0
130.3
877.5
1624.1
333.2
RhodeIsland
3.6
10.5
86.5
201.0
1489.5
2844.1
791.4
SouthCarolina
11.9
33.0
105.9
485.3
1613.6
2342.4
245.1
SouthDakota
2.0
17.9
155.7
570.5
1704.4
147.5
Tennessee
29.7
145.8
203.9
1259.7
1776.5
314.0
Texas
33.8
152.4
208.2
1603.1
2988.7
397.6
Utah
3.5
20.3
68.8
147.3
1171.6
3004.6
334.5
Vermont
1.4
15.9
30.8
101.2
1348.2
2201.0
265.2
Virginia
23.3
92.1
165.7
986.2
2521.2
226.7
Washington
4.3
106.2
224.8
1605.6
3386.9
360.3
WestVirginia
13.2
42.2
90.9
597.4
1341.7
163.3
Wisconsin
2.8
12.9
52.2
63.7
846.9
2614.2
220.7
Wyoming
21.9
39.7
173.9
811.6
2772.2
282.0
1、1)分别用样本协方差矩阵和样本相关矩阵作主成分分析,二者的结果有何差异?
2)原始数据的变化可否由三个或者更少的主成分反映,对所选取的主成分给出合理的解释。
3)计算从样本相关矩阵出发计算的第一样本主成分的得分并予以排序.
2、从样本相关矩阵出发,做因子分析。
1、1)总体主成分的定义、求法、性质和标准化变量的主成分;
2)样本主成分。
2、1)因子分析的原理及求法;
2)因子分析的性质。
1、主成分分析过程的主要语句形式为:
PROCPRINCOMPoptions;
(1)PROCPRINCOMPoptions;
此语句意味着执行主成分分析,其中的“options”可包括以下内容的部分或全部:
①DATA=SASdataset:
指出要分析的SAS数据集名称.这个数据集可以是原始观测值的SAS数据集,也可以是相关矩阵或协方差矩阵.若是后者,需要在数据集名称后加上“(TYPE=CORR)”或“(TYPE=COV)”.若省略数据集选项,则自动使用最新建立的SAS数据集.
②OUT=SASdataset:
命名一个输出的SAS数据集,其中包含原始数据以及各主成分的得分(即各主成分的观测值).
⑧OUTSTAT=SASdataset:
命名一个包含各变量的均值、标准差、相关矩阵或协方差矩阵、特征值和特征向量的输出SAS数据集.
④COVARIANCE(或COV):
要求从协方差矩阵出发作主成分分析.若省略此选项,则从相关矩阵出发进行分析.除非各变量的度量单位是可比较的或已经过某种方式的标准化,否则不宜使用此选项,应从相关矩阵出发作主成分分析.
⑤N=n:
指定要计算的主成分个数“n”.其默认值为参与分析的变量个数.
⑥PREFIX=name:
规定各主成分的名称的前缀.省略此句则SAS系统自动赋予各主成分名称分别为PRIN1,PRIN2,….若“name=A”,则各主成分名称分别为A1,A2,….前缀的字符个数加上后面数字位数应不超过8个字符.
(2)VARvariables;
此语句中的“variables”部分列出数据集中参与主成分分析的变量名称.若省略此句,则被分析数据集中所有数值变量均参与分析.
2、因子分析过程的主要语句形式为:
PROCFACTOR


- 配套讲稿:
如PPT文件的首页显示word图标,表示该PPT已包含配套word讲稿。双击word图标可打开word文档。
- 特殊限制:
部分文档作品中含有的国旗、国徽等图片,仅作为作品整体效果示例展示,禁止商用。设计者仅对作品中独创性部分享有著作权。
- 关 键 词:
- 数据分析 12132 数据 分析 实验 指导书
 冰点文库所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
冰点文库所有资源均是用户自行上传分享,仅供网友学习交流,未经上传用户书面授权,请勿作他用。
 《篮球行进间单手低手投篮》教学设计.docx
《篮球行进间单手低手投篮》教学设计.docx
-
《饲料添加剂管理条例》知识竞赛试题及答案要点.docx
-
4 物理届高三上学期第一次月考物理试题.docx
-
08第二学期研究生英语.docx
-
31氧气的性质与用途个案教学设计.docx
-
0225变电安规二次题库474道.docx
-
1992年大学英语四级.docx
-
Arts 专项练习.docx
-
《两只鸟蛋》说课稿.docx
-
《孙权劝学》选择阅读带答案.docx
-
《在操场上》教学反思.docx
-
4VMware FT容错原理与配置详解.docx
-
8套专升本艺术概论试题.docx
-
17秋学期《食品安全与日常饮食尔雅》在线作业2.docx
-
3500词汇40篇文章.docx
-
AST中央企业班组长岗位管理能力资格认证三期模拟10300009.docx
-
GMC大赛手册中文版.docx
-
JAVELIN智能球机.docx
-
P1口语重点题型素材更新版.docx
-
QMS质量管理体系审核员真题精选.docx
-
U2t2学教设计.docx
-
XX公路施工组织设计建议书.docx
-
XX省XX县治安拘留所工程建设项目可行性研究报告.docx
-
yy政治知识汇总架构.docx
-
安全生产违法行为行政处罚汇编.docx
-
百度网站的商业运营模式和盈利模式分析.docx
-
保险经营管理重点.docx
-
北极星群和山东群倾情奉献高考题解析5重庆卷.docx
-
《内科学》教学大纲.docx
-
《小学生数学报》全册苏教版六年级下.docx
-
5湖北省三类人员电工试题.docx
-
10食品经营过程与控制制度.docx
-
英语雅思机经场景题型分类汇总.docx
-
塔架生产流程及质量控制计划.docx
-
消防演练方案 汇总12.docx
-
中国船舶行业分析报告范本.docx
-
计算机网络实验带截图.docx
-
唐山市《全国未成年人思想道德建设工作测评体系》任务细则.docx
-
小区物业管理系统本科毕业设计论文.docx
-
技术部研发项目管理制度.docx
-
江西版小学四年级下册美术教案.docx
-
天津建筑工程计价办法.docx
-
交通安全伴我行演讲稿12篇.docx
-
优选Scratch教学工作计划.docx
-
调研汇报在领导来开发区调研时的汇报材料.docx
-
砼强度评定标准版1.docx
-
加油站生产安全事故案例分析.docx
-
中考物理试题汇编电路.docx
-
图文雅思口语part2物品类.docx
-
家长学校教师教学工作总结精选汇编.docx
-
外国近现代建筑史试题库资料.docx
